Methodology
Everything you need to evaluate the study: the recommendation premium, the corpus, the four models, the two rewrite conditions and their prompts, how rewrites were scored, the faithfulness judge, the confidence intervals, and an honest account of what the design does not control for.
What we measured
The study has one central quantity: the recommendation premium. For each page and each model, we computed the score gain from a rewrite guided by the recommendations, then subtracted the score gain from a free rewrite of the same page by the same model. What is left is the part of the gain attributable to the recommendations rather than to rewriting in general. A positive premium means the recommendations beat a free rewrite; a premium near zero means they did not.
The pages
The corpus is twelve real public pages, each from a different domain, covering topics from social media strategy and employee monitoring to asset tracking, balance-transfer cards, and developer documentation. We chose pages whose original coverage score sat between roughly 0.27 and 0.64: above the floor where a page is too broken to rewrite in one pass, and below the ceiling where a page is already complete and has no room to improve. The set spans five different retrieval roles (explain, guide, compare, evaluate, and convert) so the result does not rest on a single kind of page.
One detail worth stating: the original score we used as the baseline was computed fresh for this study, by re-scoring each page's text through the same pipeline used on the rewrites. Stored scores from earlier analyses drifted from a fresh re-score by as much as fifteen points, so anchoring every comparison to a fresh baseline keeps the deltas honest.
The four models
Four writing models across three families ran every page in both conditions. Each received the same page and the same prompt; we deliberately did not tune a prompt per model, because the question was whether a model can act on the recommendations as given, not whether we can coax it into doing so.
The two conditions
Three scoring points per page: the baseline (the original, unchanged), the recommendations-guided rewrite, and the free rewrite. The baseline is one score per page. The two rewrites run on all four models.
Both rewrites shared one system instruction: preserve the topic, the factual claims, the format, and the voice, and change only what the instructions require. The recommendations-guided prompt then added the list:
The free rewrite withheld the list and asked only for a more complete page. We strengthened this prompt after a pilot, because a vague “improve this” let some models return the page nearly unchanged, which would have flattered the premium:
How we scored
Every rewrite was scored exactly the way the tool scores any page, with no special handling. The scorer maps the concepts present in the text and grades how thoroughly the page answers the core questions a reader brings to its topic, then combines the two into a single structural coverage score between zero and one. The same procedure produced the baseline and both rewrite scores, so no two conditions are measured on different rulers.
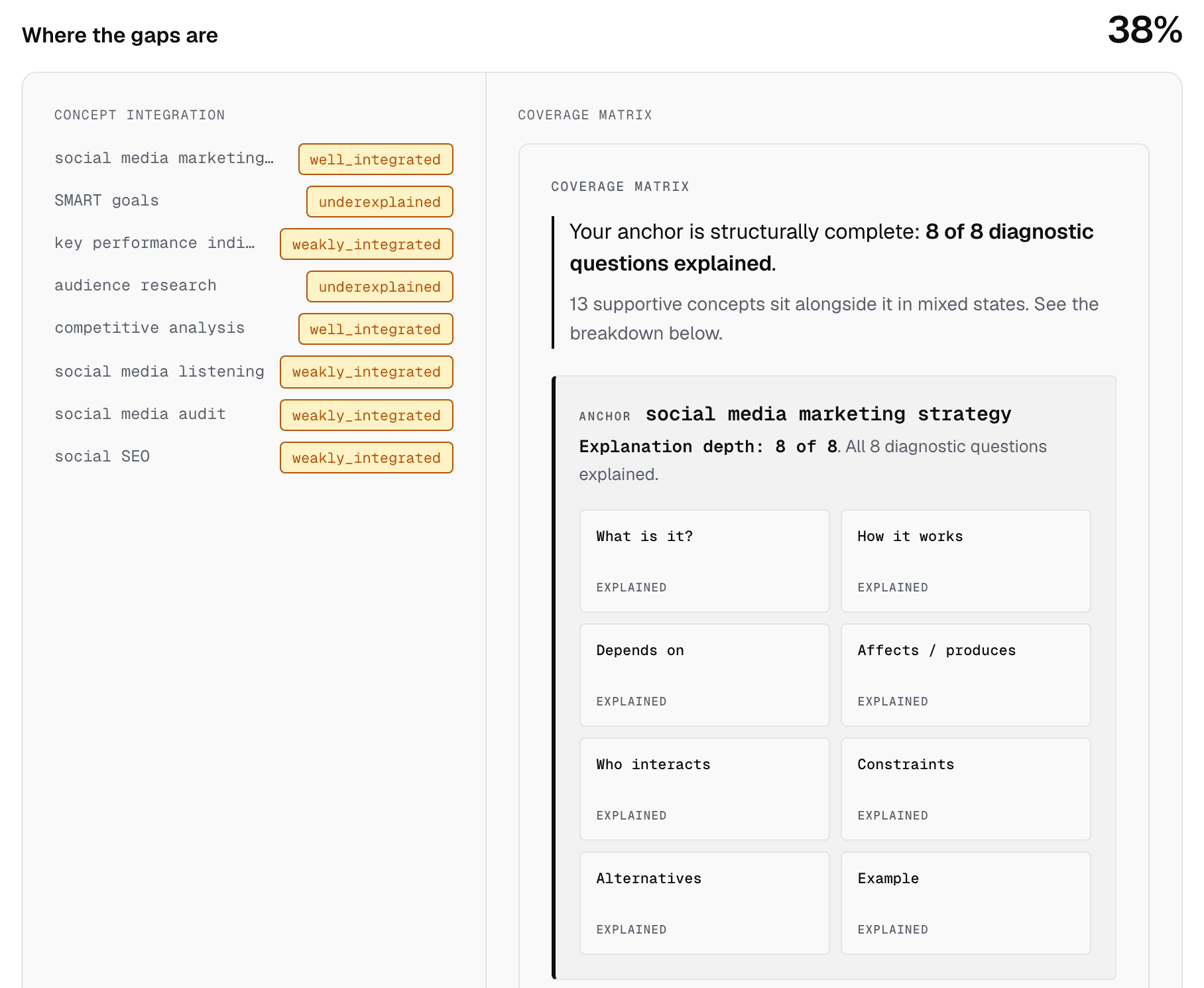
One safeguard matters here. The scorer can infer a page's primary topic from its text, and a rewrite that shifts framing could be scored against a different topic, making the numbers incomparable. To prevent that, we fixed each page's topic anchor to the original analysis's anchor and used it for the baseline and both rewrites. The scorer never re-inferred a new anchor from a rewrite.
We also checked the scorer against itself. Scoring one page's original text twice produced scores 1.3 points apart, well inside the gains we report, so run-to-run scorer noise is not driving the results.
The faithfulness judge
The coverage score measures structure, not obedience. To measure obedience separately, a judge read each recommendations-guided rewrite and graded every recommendation on a three-point scale: not addressed, mentioned but not elaborated, or substantively addressed. The share scored at least “mentioned” is the faithfulness rate plotted against the score gain on the main page. This is a secondary metric, and it has limits: it is a single pass, and it can credit a rewrite for naming a concept without checking that the explanation is correct.
The judge returned malformed output on three of the twelve pages across all models, so faithfulness figures rest on the nine pages where every model's rewrite parsed cleanly. The coverage scores are independent of the judge and were unaffected.
Bootstrap confidence intervals
To decide whether a premium was real or noise, we resampled each model's per-page premiums with replacement two thousand times, took the mean each time, and kept the middle 95% of those means. When that interval sits entirely above zero, the premium is unlikely to be a fluke of which pages happened to be in the corpus. Only GPT-4.1's interval cleared zero. We report the count of valid pages alongside every model, because a few rewrites failed to generate or score and were excluded rather than counted as zero.
What this study does not control for
The scorer shares a maker with one writer.The structural scorer uses Claude Sonnet 4.6. Sonnet 4.6 is also one of the four writer models in this study. Sonnet's rewrite scores may carry a small self-grading bias that we cannot fully rule out. We did not change the scorer mid-study, because swapping it would have introduced a different and larger confound: two methodologies in one comparison.
Length is a confound, and we kept it visible rather than removing it. Longer rewrites have more room to add structure, and the coverage score rewards added structure. We tracked the length ratio of every rewrite and report it on the data page. We did not exclude long rewrites from the score deltas, because excluding them would introduce a selection bias of its own. Instead we show the relationship directly, because the relationship is part of the finding.
GPT-4.1's control was weak.On half its pages, GPT-4.1's free rewrite changed almost nothing, even under the strengthened prompt. That makes its premium partly a statement about a lazy control, not only about strong recommendation-following. Both readings are in the report.
One corpus, one task. Twelve pages from twelve domains is enough to show the shape of the result, not to pin exact numbers. And the task is narrow: implementing structural recommendations on explanatory pages. None of this measures factual accuracy or reading quality.
Artifacts
The selected corpus with fresh baselines, the full rewrite text for every model and condition, the per-rewrite scores, the faithfulness judgements, and the aggregate statistics with confidence intervals are persisted as JSON and text in the project repository.
Every figure on this page is reported on the data page with its counts.