Can a model follow a structural recommendation?
We gave four writing models a structural to-do list and asked each to rewrite the same pages. The recommendations helped. For three of the four models, though, simply saying “make this page more complete” helped just as much.
The short answer: yes, a model can act on the recommendations, but you usually cannot tell from the score alone. Every model we tested used the recommendations to raise its structural coverage score. Only one of them, GPT-4.1, gained more from the recommendations than it did from a free rewrite with no recommendations at all.
The reason matters more than the ranking. When the other three models were told only to make a page more complete, they padded it, and padding raises the coverage score on its own. So the recommendations added little on top. This page is the report on what the recommendations were actually worth, and on why a higher score does not always mean a model did what it was told.
What we were testing
When ContentGrapher analyzes a page, it produces a ranked list of structural recommendations: specific instructions to add a missing concept, clarify one that is present but thin, or move one that belongs on a different page. We had never measured whether a writing model can take that list and act on it. So we did. We fed twelve real public pages to four models and asked each to rewrite the page to address the recommendations.
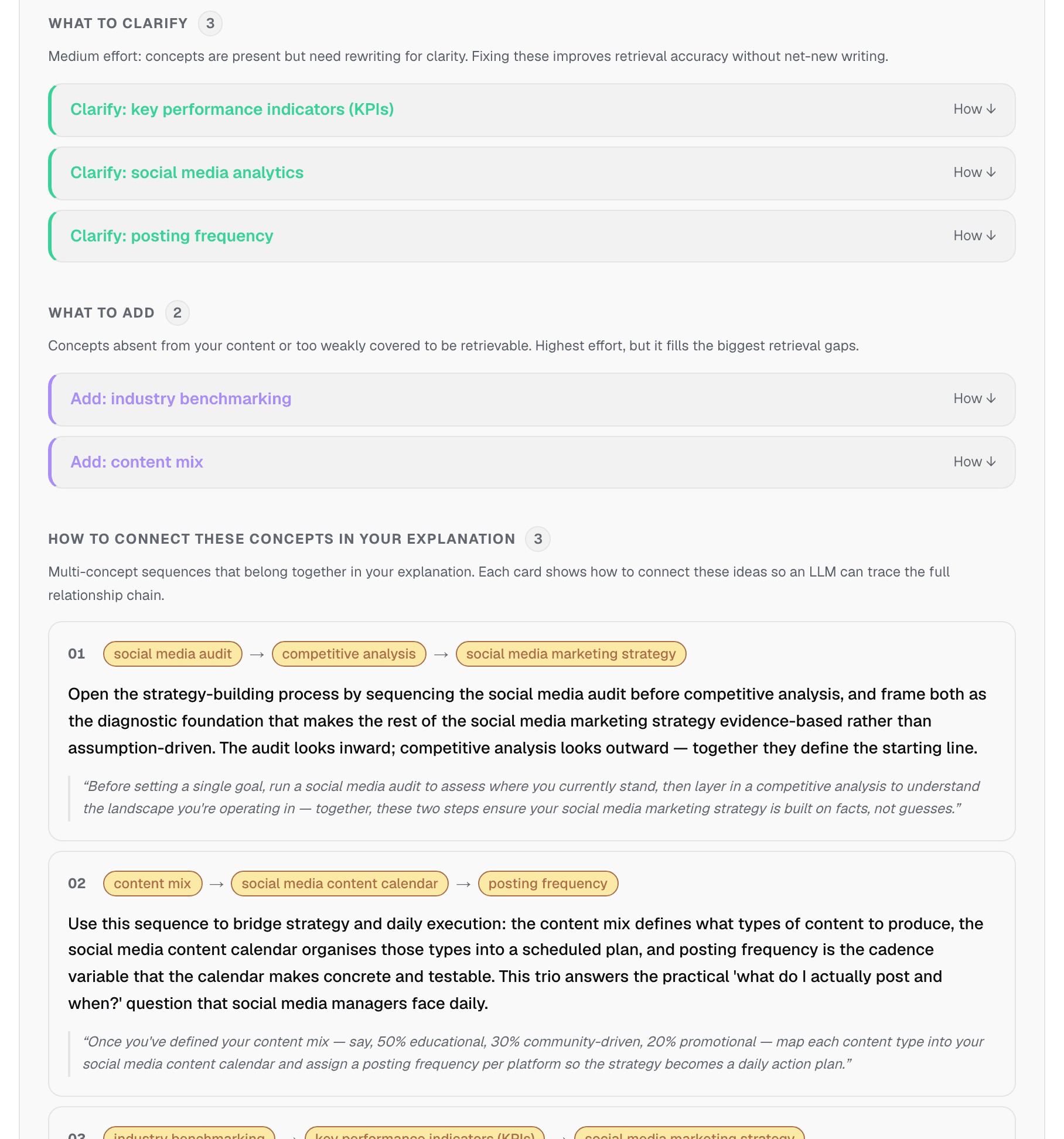
The pages were real, from sites covering social media, employee monitoring, asset tracking, balance transfers, developer docs, and more. None were already complete, and none were so thin that a single rewrite could not help. We scored every rewrite the same way the tool scores any page, using the structural coverage score, and compared it to the original page's score.
The control condition
A rewrite improving the score does not prove the recommendations did the work. Any competent rewrite might improve a thin page. So we ran a second condition on every page and every model: a free rewrite, told only to make the page more comprehensive, with the recommendations withheld. The difference between the two, the recommendation-guided rewrite minus the free rewrite, is what we call the recommendation premium. It is the part of the gain you can attribute to the recommendations rather than to rewriting in general.
Each model rewrote the same pages twice: once given the structural recommendations, once told only to improve the page. The bars are the average score gain over the original. The premium is the gap between them. Only GPT-4.1 gained meaningfully more with the recommendations than without.
What we found
Every model improved the original page when it was given the recommendations, by six to ten points on average. So the recommendations are legible: a model can read the list and raise the score. But the premium, the gain over a free rewrite, was small or negative for three of the four models. Only GPT-4.1 showed a clear premium of about eight points.
To be sure the premium was real and not noise, we resampled each model's per-page premiums two thousand times and took the middle 95% of the results. A premium is safe to act on only when that whole range sits above zero.
A premium is real only if its whole interval sits to the right of zero. GPT-4.1 is the only one that clears the line. For the other three the interval straddles zero: with this corpus we cannot say the recommendations beat free rewriting at all.
GPT-4.1 is the only model whose interval clears zero. For Claude Sonnet, DeepSeek, and Qwen, the interval crosses zero, which means that on this corpus we cannot say the recommendations beat a free rewrite at all.
Why: the length trap
The explanation is in how the models rewrite when left to their own devices. Told only to make a page more complete, three of the four models roughly doubled its length. GPT-4.1 did not: its free rewrites came back about the same length as the original, sometimes shorter.
That matters because the coverage score rewards added structure, and a longer rewrite has more room to add it. The pattern is hard to miss: the more a free rewrite padded the page, the more its score rose.
So for the three models that pad, the free rewrite was already lifting the score on its own, and the recommendations had little left to add. GPT-4.1 was the exception precisely because it does not pad: with nothing to inflate the score, the recommendations were the only thing moving it. The premium is real for GPT-4.1, but part of why it looks large is that GPT-4.1's free rewrites barely tried. On half the pages, its free rewrite changed almost nothing.
Following the list did not buy the score
We also had a separate model read each recommendation-guided rewrite and grade, for every recommendation on the list, whether the rewrite ignored it, mentioned it, or substantively addressed it. This gives a faithfulness score: how much of the list the model actually acted on, independent of the coverage score.
If the recommendations were the active ingredient, the rewrites that followed the list most faithfully should have gained the most. They did not.
There is essentially no relationship between how much of the list a model followed and how much its score rose. GPT-4.1 followed the list most faithfully, addressing about nine in ten recommendations and substantively covering seven in ten, yet on any given page that fidelity did not translate into a larger gain. The score moved with how much was added, not with whether the right things were added.
What this means for the tool
Two things are true at once, and both are useful. The recommendations are actionable: every model used them to beat the original page, and the model that refuses to pad needed them to improve at all. But the coverage score on its own cannot tell you whether a model followed the recommendations or just bulked up the page. Bulk lifts the score about as much as fidelity does, and fidelity does not predict the lift.
The reading for ContentGrapher is that the score is a necessary signal, not a sufficient one. The tool is reliable as a diagnostic: it tells you what is missing, and that is its core value. Turning “identified” into “fixed” still needs a check the score does not provide by itself, a look at whether the additions are the right ones. That is the gap between a diagnostic and an autograder, and it is honest to name it.
What this study does not show
- 01It does not measure whether the rewrites are factually accurate. Models invent things when they expand content, and a higher structural score says nothing about whether the new sentences are true.
- 02It does not measure reading quality. A page can score well on structure and still be worse to read. We measured coverage, not craft.
- 03It does not show that a higher coverage score means better answers from an AI search engine. Whether closing these gaps helps retrieval is a separate question we test in the findability study.
- 04It is not a ranking of writing ability. The comparison is scoped to one task: implementing structural recommendations on explanatory pages. A different task would order the models differently.
The answer
A model can follow a structural recommendation, and the recommendations are worth giving. But the gain you see in the score is mostly the gain from rewriting, and only one of four models turned the recommendations themselves into a clear advantage. The other three reached a similar score by padding, whether or not they read the list. The practical lesson for anyone using a model to act on a content audit: a rising score is a prompt to check the work, not proof the work was done.
This study sits next to the findability study, which asked whether acting on these calls improves what an AI search engine can answer, and the reliability study, which asked whether two models even make the same call. That pair was about the analysis. This one is about the output: what happens when a writing model receives the analysis and tries to implement it.