Structural Recommendations Now Wait for Depth
You can now trust that a "move this to its own page" recommendation means the idea is ready to carry a page — not just that it exists. The pipeline now checks whether a concept is developed enough before it suggests structural action.
Problem
Structure is how you deliver depth. It is not a substitute for it. A new page built on an underdeveloped concept fails retrieval for the same reason as the original — the problem moves to a new URL, it does not get solved.
For instance, imagine a page on social media marketing that mentions Instagram Reels strategy in a single paragraph. ContentGrapher flags it — "this idea deserves its own page." You build the page. The page has the same single paragraph on it, now at a new URL. An AI gets asked "how do I build an Instagram Reels strategy?" and still cannot answer. The content was never there. Moving the paragraph did not write it.
That is what a lot of the structural recommendations this tool was producing would have led to.
Context
I spent June running studies. Ten of them. The first one proved the tool works. The rest spent the remaining weeks explaining why I had been getting the right answer for the wrong reason.
The Findability Study came first. I built 30 pages ContentGrapher recommended, asked 166 real search questions, and got an 84% answer rate. Without the pages: 4%. I was confident in it. Build what the tool says to build, AI finds the answers.
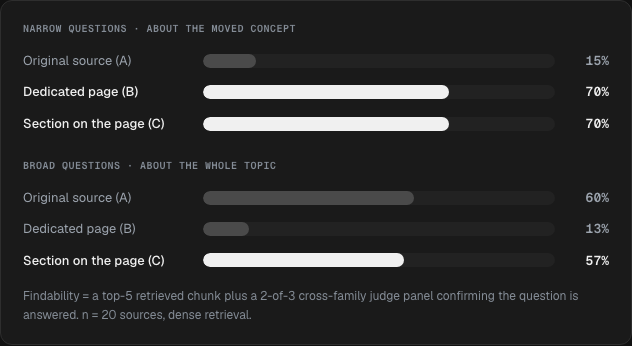
The Architecture Study asked the question I should have asked in the first study: does it have to be a new page? I took 20 pages, developed one buried concept three ways — dedicated URL, developed section on the existing page, original left alone — and asked 160 questions. A dedicated page and a developed section both came in around 70%. The original: 15%. Creating a new URL was not what lifted retrieval. Adding depth was. The two things had been happening together in the first study and I had been giving credit to the wrong one.
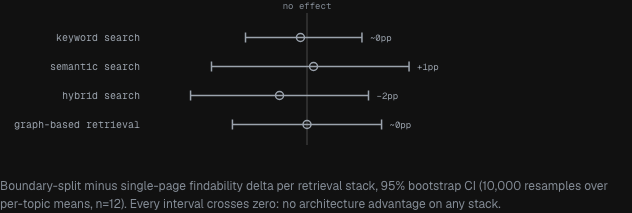
The Personalisation Study settled it. I held the total information budget constant — same writing, different architectures — split 12 topics four different ways, and measured answer-findability for 192 readers across four retrieval stacks: BM25 keyword search, dense semantic search, hybrid, and GraphRAG. The recommended split did not beat a single combined page on any of them.
The GraphRAG result is the one worth sitting with. Graph-based retrieval builds a knowledge graph across your documents — it is the system you would expect to care most about how your content is divided up. It returned a delta of exactly zero. Not close to zero. Zero. When you control for what is actually written, even the retrieval method most likely to reward page structure did not notice the structure was there.
So I ran an audit of every MOVE and CREATE recommendation the pipeline had ever fired. 31.5% of them were landing on concepts that were weakly integrated or underexplained, where the only reason given was that the concept needed more depth. Those were depth diagnoses. The tool had been handing them back as structural recommendations, and nobody had caught it, because the first study made the tool look like it was working — and it was, just not for the reason I thought.
What changed
Here is what the research pointed to.
Structural recommendations now check depth first. When a concept is underdeveloped and the only reason for recommending a move is that it needs more depth, the pipeline now says KEEP. The concept stays, the depth diagnosis surfaces in writing guidance where it belongs, and you are not sent to build a page that will fail for the same reason.
There are two exemptions. If a concept has a genuinely different retrieval role — a tutorial buried in a reference guide, say — that is a structural reason independent of depth, and the tool still recommends a move. I adjudicated this trigger post-ship: 14% false-positive rate, it is holding up. The second exemption, for concepts that belong to a different task stage, is being tightened. Post-ship adjudication returned a 60% false-positive rate on that trigger — the pipeline was applying it to concepts that were simply mentioned as a next step, or that the target audience already knows. Prompt-level fixes are scoped and will ship separately.
Writing guidance now renders above the architecture panel. The reading sequence used to let you reach the architecture panel first. Depth guidance is now above it, because that is the work that comes first.
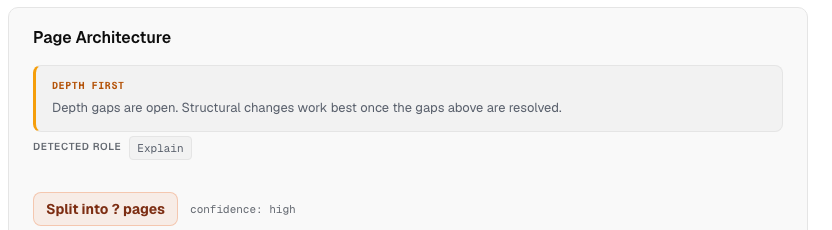
A callout appears when there is depth work still open. When the analysis recommends splitting and there are still open depth gaps, a notice sits at the top of the architecture panel: "Depth gaps are open. Structural changes work best once the gaps above are resolved." It disappears when the depth work is done.
The coverage score now weights depth and integration equally. Integration was previously weighted at 60%, question coverage at 40%. They are now 50/50. I checked this against 1,318 analyses before shipping. The maximum shift was 2.8 percentage points across the whole corpus. Most scores are unchanged.
CREATE recommendations are now grounded in the ideal explanation framework. When the pipeline suggests creating a new page, it now knows what the ideal framework for your topic looks like — which concepts belong at the core, which are supporting, which are peripheral. Previously it was working only from what was already on the page. Now it can see the gap between what should exist and what does, and reason about whether a new page actually closes it.
What did not change: the audit methodology, the Phase 1 ensemble, the boundary decision schema, the ordinal depth rubric. The research validated those. What changed is what the pipeline does with the diagnosis once Phase 1 produces it.
The research kept coming back to the same thing. You cannot fix a depth problem with structure. The tool now reflects that.