The Decoy Study Validates the Gap Picks
You can now read a controlled study showing that ContentGrapher's gap picks lift AI retrieval by 11 percentage points more than adding the same volume of content to parts the page already covers, on pages with five or more flagged gaps.
Problem
Context
Why now
What changed
The Decoy Study is live at contentgrapher.io/research/decoy-study. Forty third-party pages were each rendered in three versions (original, treatment, decoy), then run through a standard retrieval pipeline with 320 questions written by two AI personas blind to the page contents.
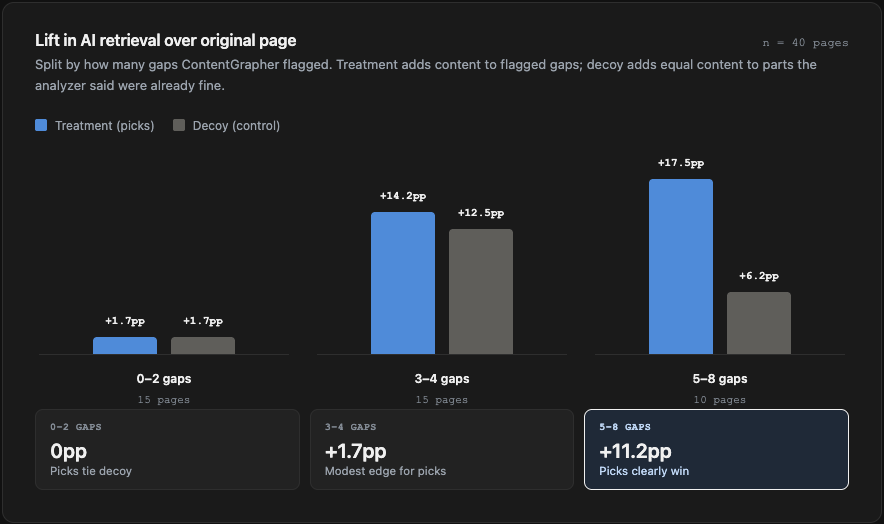
The headline finding is the split. On pages with five or more flagged gaps, the analyzer's specific picks lifted retrieval by 11.2 percentage points more than the decoy. On pages with two or fewer, the two arms moved retrieval by the same amount. This makes the gap count itself a signal: when ContentGrapher flags a lot of gaps, which gap you fill matters; when it flags few, the page is already close to complete and any structural addition helps about the same.
The study page links to the full methodology, the per-page data, and a NotebookLM demo. One page that did not fit the pattern is also reported in full.